
LLMs.txt and AI Visibility. Test It, Measure It, but Do Not Treat Google as the Final Authority.
As businesses try to understand how their brands appear in ChatGPT, Gemini, Claude, Perplexity and other AI platforms, a new technical file has started receiving attention: llms.txt. Some SEO/GEO specialists describe it as the AI equivalent of robots.txt. Others present it as a way to improve visibility in generative search results. Both descriptions need qualification. An llms.txt file may help an AI system understand the most important information on a website, but it is not an established AI mentioning factor. It does not guarantee discovery, citations or recommendations. That does not necessarily make it useless. The more rational position is to understand what the file is designed to do, deploy it only where appropriate, and measure whether it produces any observable benefit.
What is an llms.txt file?
An llms.txt file is a proposed website file designed to help large language models and AI agents find and understand a website’s most relevant content.
It is normally placed in the root directory of a domain:
https://example.com/llms.txt
The file is generally written in a simple, human-readable Markdown format. It may contain:
- a short description of the organisation;
- links to important products or services;
- technical documentation;
- pricing or plan information;
- policies and terms;
- research or evidence;
- contact and support resources;
- explanations of what each linked page contains.
The purpose is to give an AI system a concise map of the website’s most useful information. Modern websites can be difficult for AI systems to interpret. Important information may be spread across navigation menus, JavaScript applications, product pages, blog articles, documentation platforms and support centres. An llms.txt file attempts to reduce that complexity by presenting selected resources in a structured and accessible format.
For example, a company could use the file to direct an AI system towards:
- its official company information;
- its principal service pages;
- verified product documentation;
- current pricing;
- frequently asked questions;
- relevant research;
- customer-support policies.
The file is therefore better understood as a content guidance document for AI systems, rather than a direct visibility or ranking mechanism.
What is the difference between llms.txt and robots.txt?
The comparison with robots.txt is useful because both files are normally stored at the root of a website. However, they have fundamentally different purposes.
Robots.txt controls crawler access
A robots.txt file provides instructions to automated web crawlers about which parts of a website they may or may not crawl.
It is commonly located at:
https://example.com/robots.txt
A typical instruction might look like this:
User-agent: *
Disallow: /private/
This tells crawlers that follow the Robots Exclusion Protocol not to crawl the /private/ directory.
The file can also:
- allow or disallow specific crawlers;
- restrict access to selected directories;
- identify the location of an XML sitemap;
- manage crawler behaviour across parts of a website.
Its main purpose is access management.
However, robots.txt is not a security mechanism. A crawler can technically ignore it, and restricted URLs may still appear in search results if they are discovered through external links.
LLMs.txt provides content guidance
An llms.txt file does not primarily tell AI systems where they are forbidden to go.
Instead, it attempts to tell them:
- what the website is about;
- which pages are most important;
- where authoritative information can be found;
- which resources may be useful when answering questions.
Its main purpose is content orientation and interpretation.
A simple example might look like this:
# Example Company
Example Company provides digital health compliance consultancy in the UK.
## Core Services
- [Clinical Risk Management](https://example.com/clinical-risk-management): Information about DCB0129 and DCB0160 services.
- [DTAC Consultancy](https://example.com/dtac): Guidance and support for NHS Digital Technology Assessment Criteria.
- [Medical Device Compliance](https://example.com/medical-device-compliance): Regulatory support for health technology software.
## Company Information
- [About Us](https://example.com/about)
- [Contact](https://example.com/contact)
This does not instruct an AI system to rank the company, recommend it or treat its claims as true.
It simply provides a cleaner route to selected information.
LLMs.txt versus robots.txt
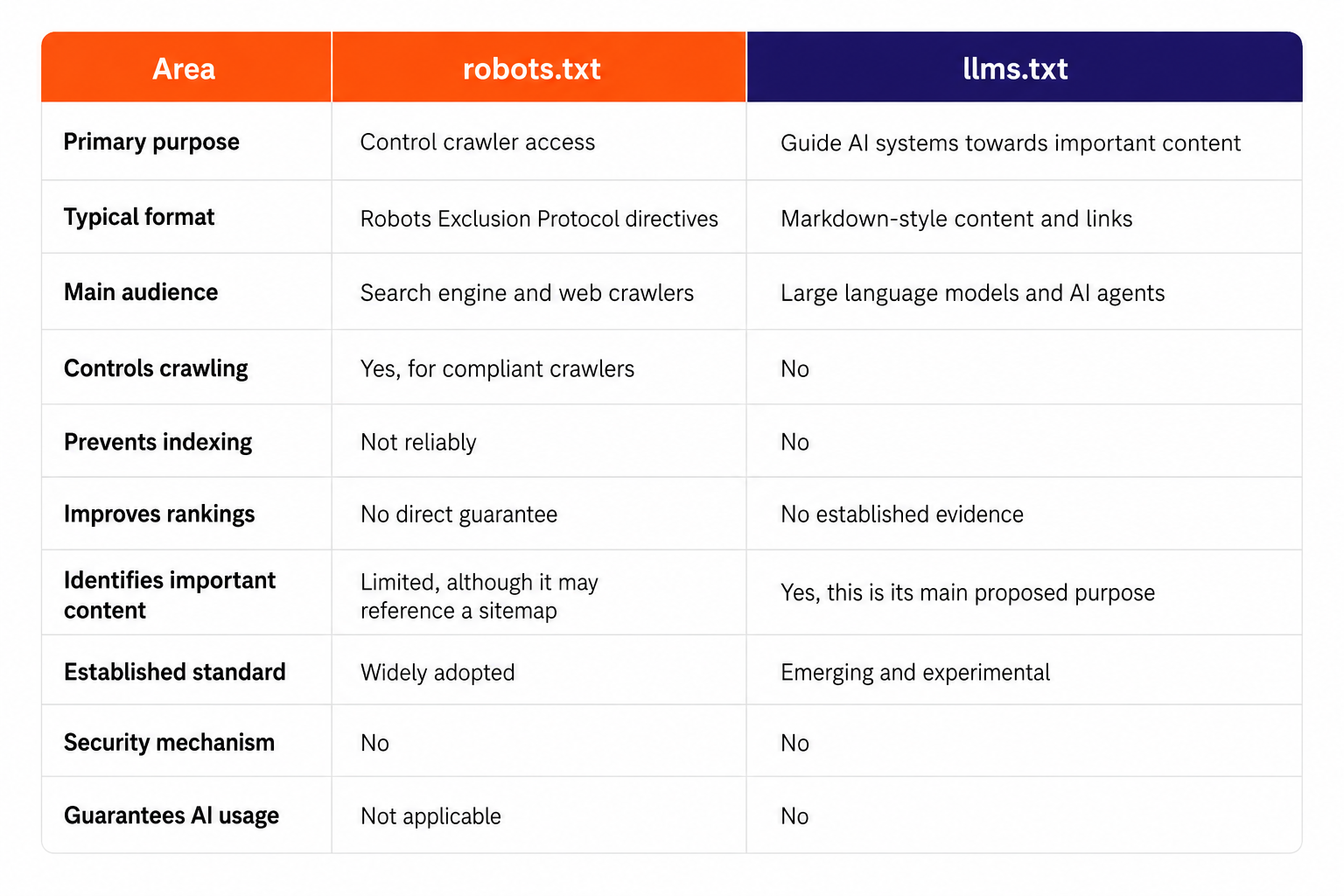
The difference can be summarised simply:
Robots.txt tells compliant crawlers where they should or should not go.
LLMs.txt attempts to show AI systems where the most useful information is located.
Calling llms.txt the “robots.txt for AI” may therefore create the wrong expectation. One file controls access, while the other proposes a content-navigation layer.
What llms.txt does not do
An llms.txt file does not automatically:
- make a website discoverable;
- force an AI crawler to visit the website;
- guarantee inclusion in AI-generated answers;
- improve rankings in Google;
- increase AI citations;
- establish brand authority;
- validate company claims;
- replace structured data;
- replace an XML sitemap;
- replace technical SEO;
- prevent content from being used by AI systems.
This distinction is essential.
A business could create an llms.txt file declaring itself the leading provider in its industry. That would not make the claim reliable.
AI systems still need independent evidence, contextual relevance, external corroboration and trustworthy source material.
The file can direct an AI system towards evidence. It cannot manufacture that evidence.
What did Google actually say about llms.txt?
A recent Search Engine Journal article examined comments from Google’s John Mueller about the limitations of llms.txt.
The central issue is that the file was not originally proposed as a discovery mechanism.
In other words, it was not intended to tell an AI platform:
“Here is my website. Please discover it, trust it and recommend it.”
Its proposed purpose is closer to:
“Now that you are already examining my website, here is a concise guide to its most important information.”
That is an important distinction.
Discovery concerns whether a platform finds, crawls and processes a website.
Retrieval and inference concern how a system accesses, selects and interprets information when answering a question or completing a task.
An llms.txt file cannot force an AI platform to discover a brand. It cannot make unsupported claims authoritative. It cannot guarantee that ChatGPT, Gemini, Claude, Perplexity or another system will cite the website.
However, that does not establish that the file has no possible utility.
It establishes that many seo / geo professionals and marketers may have assigned it the wrong function.
The real flaw may be the expectation, not the file
The problem begins when llms.txt is presented as a shortcut to AI visibility.
It is not a substitute for:
- authoritative and original content;
- technically accessible pages;
- strong internal information architecture;
- consistent brand entities;
- credible external references;
- structured data;
- independent reviews;
- expert contributions;
- relevant digital PR;
- conventional search visibility.
A self-published file cannot make an AI system believe that a company is a market leader simply because the company says so.
This is the trust problem identified by Google. Every business could use its file to declare that its products are the best, its services are unique and its experts are the most qualified.
AI systems still need corroborating evidence.
However, that criticism applies mainly to the claims placed inside the file. It does not necessarily invalidate the concept of providing a machine-readable guide to important resources.
An XML sitemap is not proof of quality either. It still performs a technical function.
An llms.txt file may similarly have a narrow navigational or interpretive function, even if it provides no direct ranking advantage.
Google Search is not the entire AI ecosystem
One of the biggest mistakes in modern SEO is interpreting a statement about Google Search as a universal statement about every AI system.
AI discovery is developing across a fragmented environment involving:
- traditional search indexes;
- retrieval-augmented generation systems;
- live web search;
- AI assistants;
- browser-based agents;
- specialist answer engines;
- enterprise knowledge systems;
- model-training pipelines;
- agentic commerce and task-completion systems.
Different systems may use different crawlers, retrieval processes and content formats.
Google may decide that llms.txt is unnecessary for AI Overviews, AI Mode or conventional search visibility. That does not prove that every current or future AI agent will ignore it. Even within Google’s ecosystem, different tools may approach the subject differently. Google Search may find no need for the file as a ranking or discovery mechanism, while auditing or agentic-browsing tools may still recognise the emerging convention. The apparent contradiction becomes easier to understand when the use cases are separated. For search rankings, the file may provide little or no value. For helping an AI agent understand a website it is already visiting, a concise content guide may still have practical utility.
These are different questions.
Why testing llms.txt can still be rational
For many websites, implementing a basic llms.txt file requires little development time and introduces minimal technical risk. That does not mean every company should prioritise it. A business with indexing problems, weak content, inaccurate product information, poor site architecture or severe performance issues has more important work to complete. But where the fundamentals are already in place, the decision should be based on effort, risk and opportunity cost. If the file takes minutes to deploy, is factually accurate, remains properly maintained and does not interfere with crawling or indexing, testing it may be entirely reasonable.
The correct standard is not:
“Has Google given us permission to use it?”
The more useful questions are:
- What hypothesis are we testing?
- Which AI platforms are relevant to the brand?
- Can we observe whether the file is being requested?
- Does implementation change the quality of AI-generated answers?
- Does the file help an agent locate important documentation?
- Is the maintenance effort proportionate to the observed benefit?
- Would another technical or content improvement create more value?
This is how responsible experimentation should work.
Deploy it. Observe it. Measure it. Keep it if it produces useful evidence. Remove it if it does not.
The SEO industry should not treat Google as the only authority
The SEO industry has a strange habit of treating Google as both defendant and expert witness in the same trial. Google operates the dominant search platform, defines much of the technical environment and then becomes the primary authority the industry consults when deciding how that environment works. Google’s guidance is important. It should be taken seriously. But it is not necessarily complete, infallible or applicable to every AI platform. Blindly accepting every new GEO tactic is irrational. Blindly dismissing an inexpensive experiment because Google is sceptical can be equally irrational.
What should an llms.txt experiment measure?
Simply publishing the file and waiting for traffic to increase is not enough. AI visibility often does not create a conventional referral click. The effects of one technical change can also be difficult to isolate. A more useful measurement framework should examine several layers.
1. Server-log activity
Check whether recognised AI crawlers or browser-based agents request the file.
Record:
- crawler or user-agent identity;
- request frequency;
- response status;
- pages requested before or after the file;
- changes following file updates.
A crawler requesting the file does not prove that it influenced an answer.
However, it confirms that the resource is at least being accessed.
2. AI answer consistency
Run a controlled group of prompts before and after implementation.
Assess whether AI platforms become more accurate when answering questions about:
- the company;
- products and services;
- pricing or eligibility;
- technical documentation;
- policies;
- locations;
- founders or experts;
- supported integrations;
- differentiators.
The prompts, platform, model version, location and testing dates should be recorded.
Without controls, normal answer variability may be mistaken for an improvement.
3. Citation and source behaviour
Track whether the brand’s pages appear more frequently as cited or supporting sources.
Do not examine only the total number of citations. Consider:
- which pages are cited;
- whether the correct page is selected;
- citation relevance;
- answer accuracy;
- recommendation context;
- competitor inclusion;
- changes across different AI platforms.
A citation to an irrelevant or outdated page may be less valuable than no citation.
4. Agent usability
Where agentic browsing is relevant, test whether an automated agent can locate and use essential information more efficiently.
For example:
- Can it identify the correct product documentation?
- Can it find a returns or cancellation policy?
- Can it distinguish between service plans?
- Can it locate the appropriate contact route?
- Can it complete a defined website task with fewer navigation errors?
This may be a more appropriate test of llms.txt than expecting an immediate increase in rankings.
5. Maintenance cost
An outdated llms.txt file may create conflicting or inaccurate information.
Measure the effort required to keep it aligned with:
- new pages;
- discontinued products;
- changed prices;
- updated policies;
- revised brand claims;
- new documentation;
- changes to contact details.
A low-effort experiment can become a poor investment if it creates another unmanaged content layer.
What should businesses include in llms.txt?
An llms.txt file should not be written as advertising copy.
It should help a machine locate accurate and authoritative information.
Useful inclusions may include:
- a concise factual description of the organisation;
- links to core service or product pages;
- documentation and knowledge-base resources;
- pricing or plan information where appropriate;
- policies and terms;
- verified company information;
- contact and support routes;
- relevant research or evidence;
- brief descriptions explaining each linked resource.
Avoid:
- unsupported “market-leading” claims;
- keyword stuffing;
- duplicated sales copy;
- outdated URLs;
- contradictory company information;
- exaggerated service descriptions;
- claims that cannot be independently verified.
The file should point systems towards evidence, not attempt to manufacture authority.
Do not sell experimentation as certainty
There is currently no strong evidence that adding an llms.txt file will independently increase AI citations or improve visibility across major platforms.
That limitation should be stated clearly.
The file should not be sold as:
- a guaranteed GEO tactic;
- an AI mentioning signal;
- a direct route into AI answers;
- a replacement for technical SEO;
- a substitute for authoritative content;
- proof that a brand is trustworthy;
- a complete AI visibility strategy.
Responsible GEO requires separating three categories of information.
Confirmed
What an AI platform has documented or what repeated testing has demonstrated consistently.
Observed
What server logs, prompt testing or platform monitoring appear to show, but which may not yet have a confirmed causal explanation.
Speculative
What may become useful or influential but has not yet been proven.
At present, llms.txt belongs largely in the experimental category. Its usefulness may vary according to the platform, website and use case.
That is a reason to test it carefully, not a reason to make absolute claims in either direction.
From Google-led SEO to evidence-led GEO
The shift from traditional search optimisation to generative engine optimisation requires a change in mindset.
SEO has historically revolved around one dominant intermediary. AI visibility is now developing across multiple models, interfaces, search systems, crawlers and agents. No single company can provide the final answer for the entire ecosystem.
Google’s position should inform an experiment. It should not replace the experiment. Blindly trusting every statement from Google is not a strategy. Blindly ignoring Google is not a strategy either.
The professional approach is to:
- define the hypothesis;
- assess the implementation risk;
- establish a baseline;
- deploy the change;
- monitor relevant platforms;
- compare the results;
- retain or remove the change based on evidence.
The question should not be whether the industry believes in llms.txt.
The question should be whether it produces a measurable benefit for a particular website.
How Luciqo AI approaches emerging GEO tactics
Luciqo AI is built around the principle that AI visibility should be measured rather than assumed.
A file, schema implementation or content change should not be declared successful merely because it has been deployed.
Its value depends on whether it changes how AI platforms:
- find the brand;
- interpret its information;
- describe its services;
- cite its content;
- compare it with competitors;
- recommend it to potential customers.
This means monitoring factors such as:
- brand presence across AI-generated answers;
- AI recommendation context;
- cited domains and individual pages;
- competitor visibility;
- recurring factual inaccuracies;
- reputation signals;
- prompt-level performance;
- changes following optimisation work.
Luciqo AI helps businesses move away from unverified GEO assumptions and towards structured analysis. Instead of claiming that an optimisation “should work”, the objective is to examine whether brand visibility, citation behaviour, recommendation patterns or answer accuracy actually change. LLMs.txt may eventually become widely adopted. It may remain useful only for specific AI agents. It may be replaced by another standard. The correct strategy is not to predict that outcome with certainty. It is to build a measurement process capable of identifying what is changing.
Google is right about one central point, llms.txt should not be mistaken for an established AI discovery or ranking mechanism. It does not perform the same function as robots.txt. Robots.txt manages crawler access and LLMs.txt attempts to guide AI systems towards selected information, neither file guarantees rankings, authority or recommendations.
But “not an established ranking factor” is not the same as “never worth testing”. For organisations with strong technical foundations and a clear AI visibility measurement process, llms.txt can be treated as a controlled, low-cost experiment. Do not deploy it simply because the GEO industry is excited about it.
Do not reject it simply because Google is sceptical. Understand what the file is designed to do. Establish a baseline. Monitor whether relevant systems access it. Test whether answers, citations or agent behaviour improve. Maintain it if it provides value. Remove it if it does not.
In an uncertain AI search environment, neither hype nor authority should replace evidence.
Ready to go?
Book a demo with our team to see how Luciqo measures your brand in AI.